|
I am currently in the MSCS program at UIUC, advised by Prof. Jiaxuan You. I am also a researcher in the MIT Brain and Cognitive Sciences department, working with Prof. Evelina Fedorenko and Dr. Andrea de Varda in the EvLab. I received my B.A. in Mathematics and Computer Science from Carleton College, a leading liberal arts college in the US. During my undergrad, I was fortunate to work with Prof. Anima Anandkumar and Dr. Rafał Kocielnik in the Anima AI+Science Lab at Caltech. I also previously interned at NVIDIA. 韩芃睿 / Email / Google Scholar / GitHub / LinkedIn / Twitter |

|
|
[Jul 2026] Honored to receive the Best Paper Award at the ICML CTB Workshop for our work on Psychometric Evaluation of LLMs! |
|
My research aims to advance scientific understanding of AI (especially neural models like LLMs), and more broadly, the general principles of intelligence and intelligent behavior. I also work on problems where current AI still falls short of biological intelligence, such as adaptivity, robustness, and sample efficiency. At the same time, I am drawn to using AI as a powerful instrument for studying open scientific questions about the human mind and brain. I approach this through four interconnected threads:
The first two threads parallel cognitive science and neuroscience in their study of mind and brain. The third draws on both to build better AI; the fourth turns that AI back on biological intelligence and scientific discovery. If any of this resonates with your interests, feel free to reach out and let's connect / collaborate! |



|
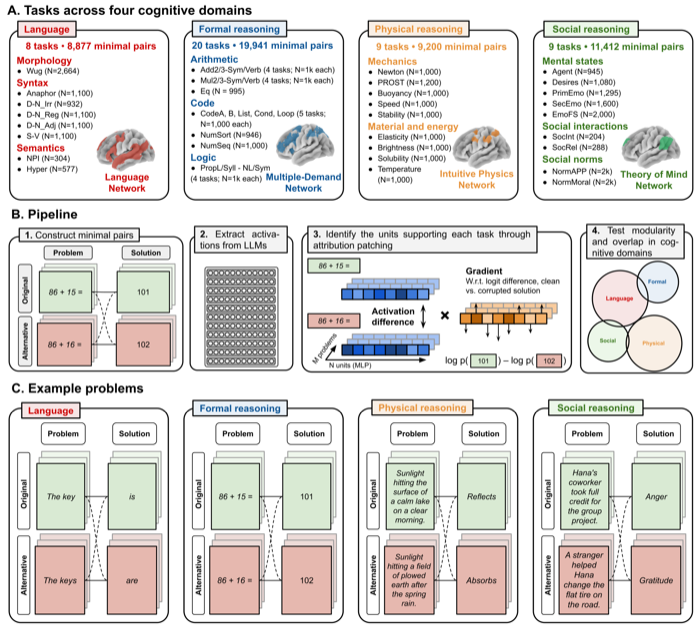
Pengrui Han, Jacob Andreas, Evelina Fedorenko†, and Andrea Gregor de Varda† († Co-senior Authors) Preprint, 2026 project / code / manuscript / thread Through circuit analyses across 46 tasks spanning language, formal reasoning, social reasoning, and physical reasoning, we find that LLMs develop a modular cognitive architecture mirroring the human brain: tasks drawing on the same network in humans recruit overlapping neurons in LLMs, whereas tasks drawing on different networks recruit distinct neurons. Modularity may be a fundamental principle of intelligent systems rather than a biological accident. |

|
Pengrui Han*, Rafal D. Kocielnik*, Peiyang Song, Ramit Debnath, Dean Mobbs, Anima Anandkumar, and R. Michael Alvarez (* Equal Contribution) International Conference on Machine Learning (ICML), 2026 NeurIPS LAW Workshop, 2025, Best Paper Honorable Mention arXiv / project / code / media LLMs say they have personalities, but they don’t act like it. Alignment today shapes language, not behavior. This linguistic–behavioral dissociation cautions against equating coherent self-reports with cognitive depth. |
|
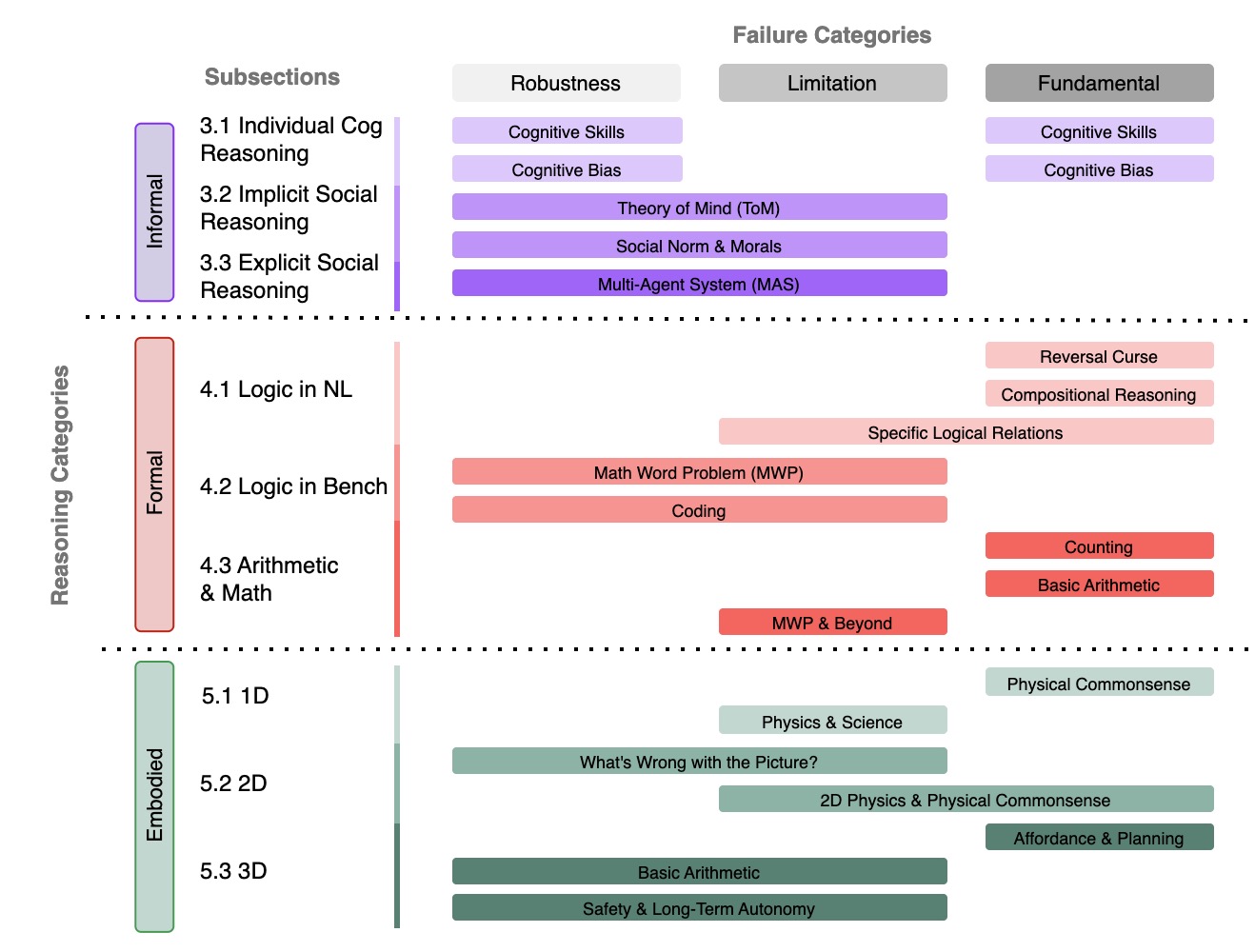
Peiyang Song*, Pengrui Han*, and Noah Goodman (* Equal Contribution) Transactions on Machine Learning Research (TMLR), 2026, Survey Certificate arXiv / code / proceeding / media We present the first comprehensive survey dedicated to reasoning failures in LLMs. By unifying fragmented research efforts, our survey provides a structured perspective on systemic weaknesses in LLM reasoning, offering valuable insights and guiding future research towards building stronger, more reliable, and robust reasoning capabilities. |

|
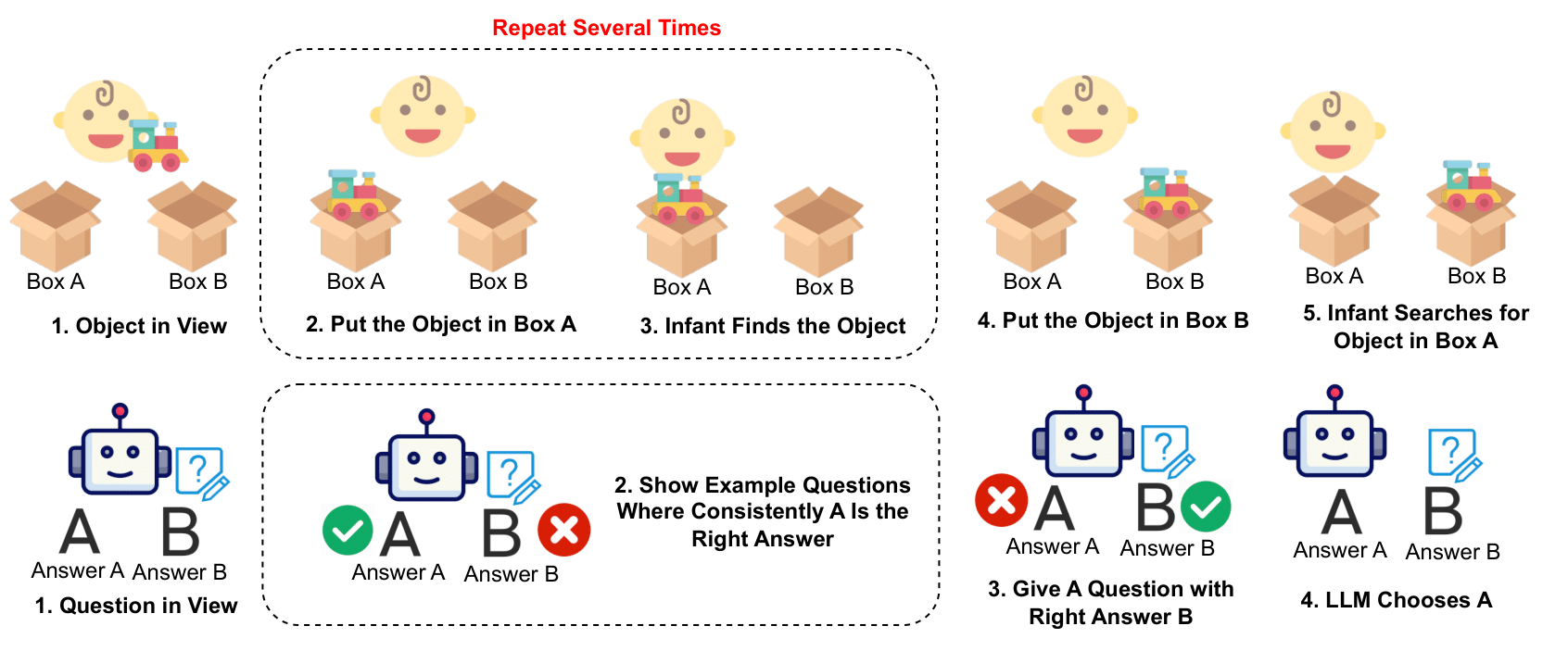
Pengrui Han*, Peiyang Song*, Haofei Yu, and Jiaxuan You (* Equal Contribution) Findings of Empirical Methods in Natural Language Processing (EMNLP), 2024 arXiv / code / proceeding Motivated by the crucial cognitive phenomenon of A-not-B errors, we present the first systematic evaluation on the surprisingly vulnerable inhibitory control abilities of LLMs. We reveal that this weakness undermines LLMs' trustworthy reasoning capabilities across diverse domains, and introduce various mitigations. |

|
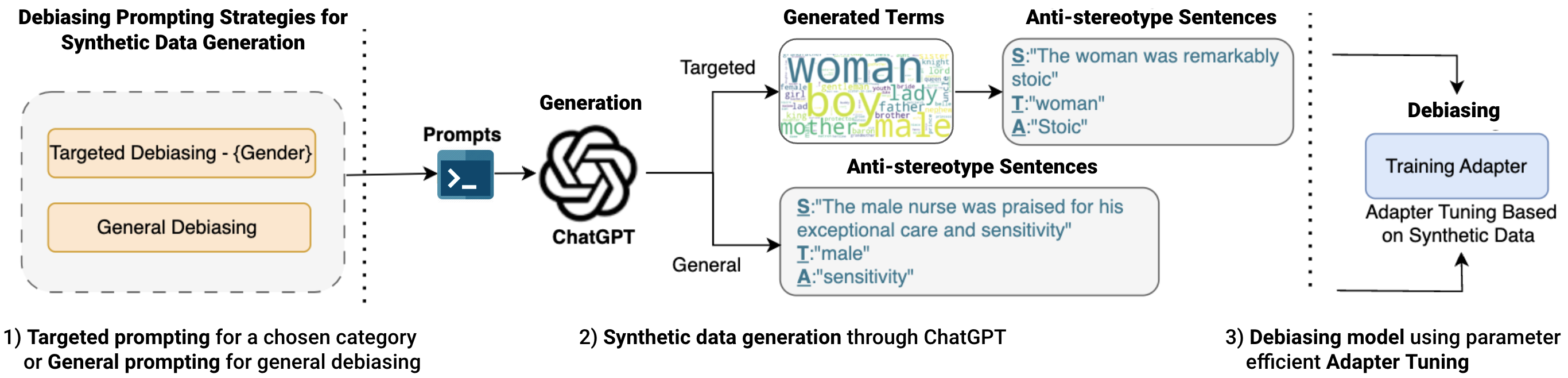
Pengrui Han*, Rafal Kocielnik*, Adhithya Saravanan,Roy Jiang, Or Sharir,and Anima Anandkumar (* Equal Contribution) Conference On Language Modeling (COLM), 2024 arXiv / code / proceeding We propose a light and efficient pipeline that enables both domain and non-domain experts to quickly generate synthetic debiasing data to mitigate specific or general bias in their models with parameter-efficient fine-tuning. |
|
|
|
|
|
Outside research, I play classical flute, hit the slopes any chance I can in winter, swim and play badminton year-round, and try to travel somewhere new every few months, usually somewhere with mountains or water. |





















|
|