Behavioral Science of AI
Understanding what models do, where they fail, and why
|
A long tradition in cognitive science and psychology seeks to understand the human mind by studying behavior — using systematic observations, controlled experiments, and characteristic failures to infer the “software” running underneath. This approach has yielded deep insights into perception, memory, reasoning, and decision-making, even without direct access to the underlying neural machinery. Today’s large language models present a parallel opportunity: they exhibit rich, complex, and sometimes puzzling behavior, and characterizing this behavior systematically — what they reliably do, where they fail, and how they compare to biological intelligence — is essential for both understanding what they are and deploying them safely.
My work takes a cognitive-science-grounded, failure-driven approach: studying specific cognitive phenomena and failures in modern LLMs A-Not-B, questioning foundational assumptions in behavioral evaluation Personality Illusion, building systematic frameworks for understanding and mitigating reasoning failures Reasoning Failures, and extending behavioral analysis from isolated prompts to interactive and agentic settings Interactive Evaluation Where Agents Fail.
|
|
The Personality Illusion: Revealing Dissociation Between Self-Reports & Behavior in LLMs
Pengrui Han*, Rafal D. Kocielnik*, Peiyang Song, Ramit Debnath, Dean Mobbs, Anima Anandkumar, and R. Michael Alvarez (* Equal Contribution)
International Conference on Machine Learning (ICML), 2026
NeurIPS LAW Workshop: Bridging Language, Agent, and World Models, 2025, Best Paper Honorable Mention
view
/
arXiv
/
project
/
code
/
media
LLMs say they have personalities, but they don’t act like it. Alignment today shapes language, not behavior. This linguistic–behavioral dissociation cautions against equating coherent self-reports with cognitive depth.
|
|
|
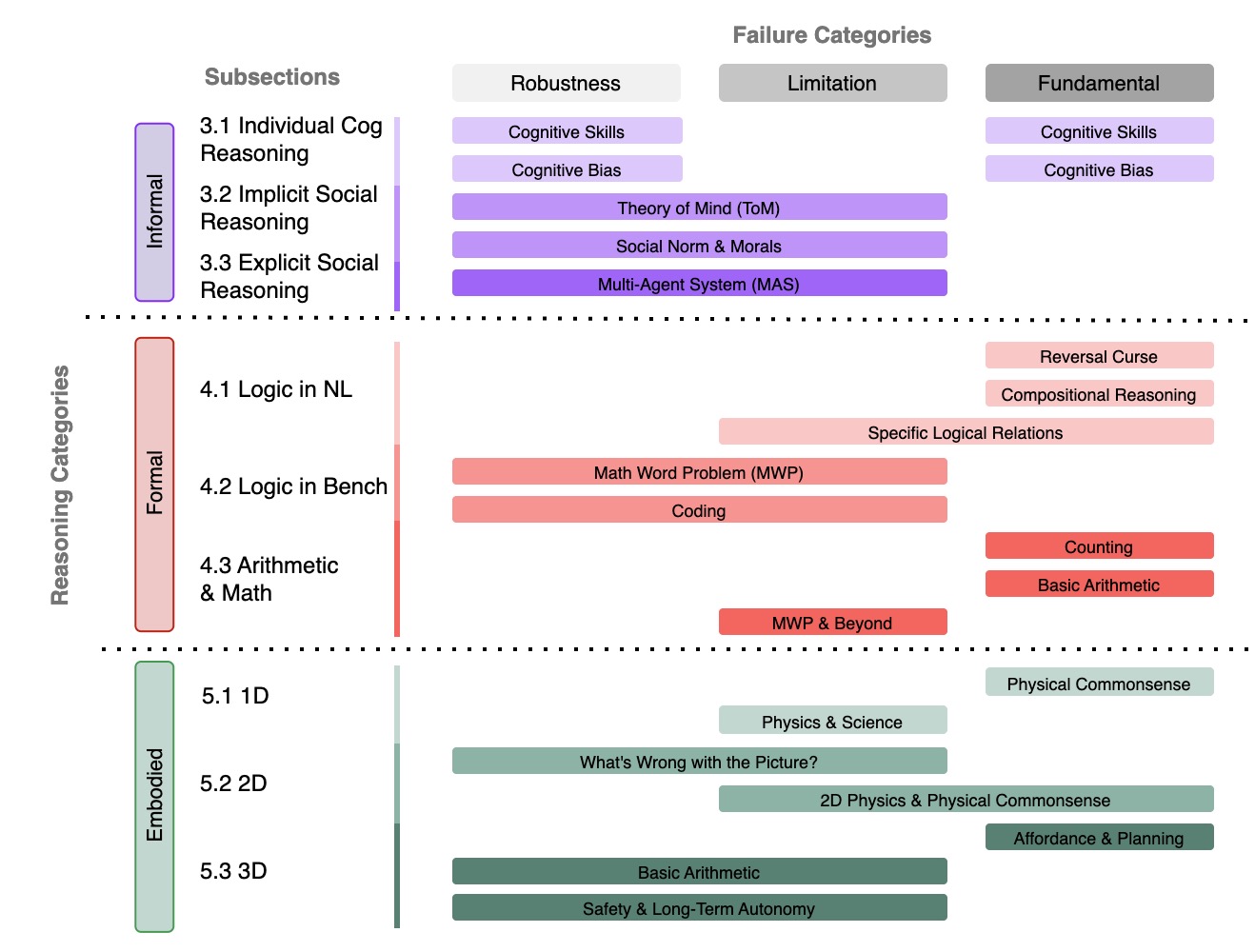
Large Language Model Reasoning Failures
Peiyang Song*, Pengrui Han*, and Noah Goodman (* Equal Contribution)
Transactions on Machine Learning Research (TMLR), 2026, Survey Certificate
view
/
arXiv
/
code
/
proceeding
/
media
We present the first comprehensive survey dedicated to reasoning failures in LLMs. By unifying fragmented research efforts, our survey provides a structured perspective on systemic weaknesses in LLM reasoning, offering valuable insights and guiding future research towards building stronger, more reliable, and robust reasoning capabilities.
|
|
|
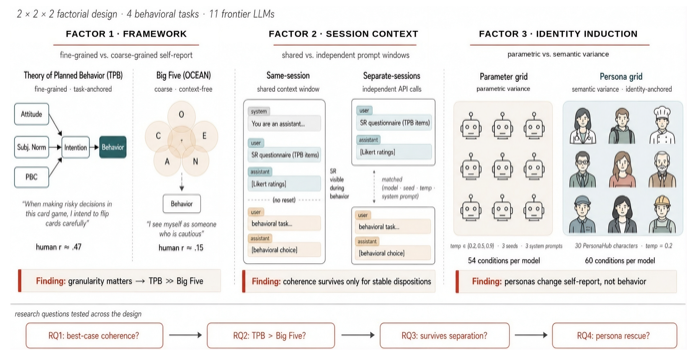
Rethinking Psychometric Evaluation of LLMs: When and Why Self-Reports Predict Behavior
Rafal D. Kocielnik, Pengrui Han, Peiyang Song, Myrl G. Marmarelis, Ramit Debnath, Dean Mobbs, Anima Anandkumar, and R. Michael Alvarez
ICML Workshop on Combining Theory and Benchmarks (CTB), 2026, Best Paper Award
view
/
arXiv
/
project
/
code
Anticipating LLM behavioral tendencies from low-cost psychometric probes is critical for safe deployment, but only if self-reports reliably predict behavior. We compare broad Big 5 traits with the Theory of Planned Behavior, which targets intentions toward specific behaviors and better predicts when self-reports translate into action.
|
|
|
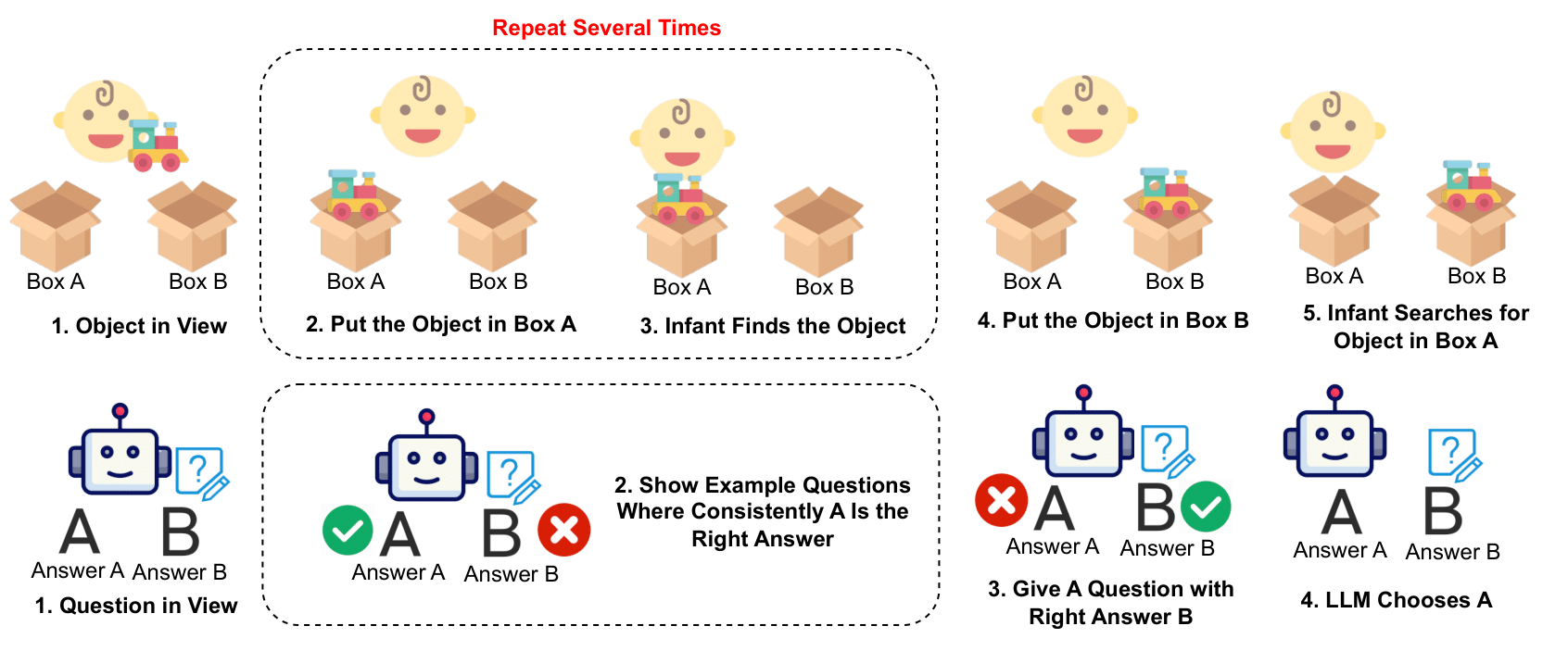
In-Context Learning May Not Elicit Trustworthy Reasoning: A-Not-B Errors in Pretrained Language Models
Pengrui Han*, Peiyang Song*, Haofei Yu, and Jiaxuan You (* Equal Contribution)
Findings of Empirical Methods in Natural Language Processing (EMNLP), 2024
view
/
arXiv
/
code
/
proceeding
Motivated by the crucial cognitive phenomenon of A-not-B errors, we present the first systematic evaluation on the surprisingly vulnerable inhibitory control abilities of LLMs. We reveal that this weakness undermines LLMs' trustworthy reasoning capabilities across diverse domains, and introduce various mitigations.
|
|
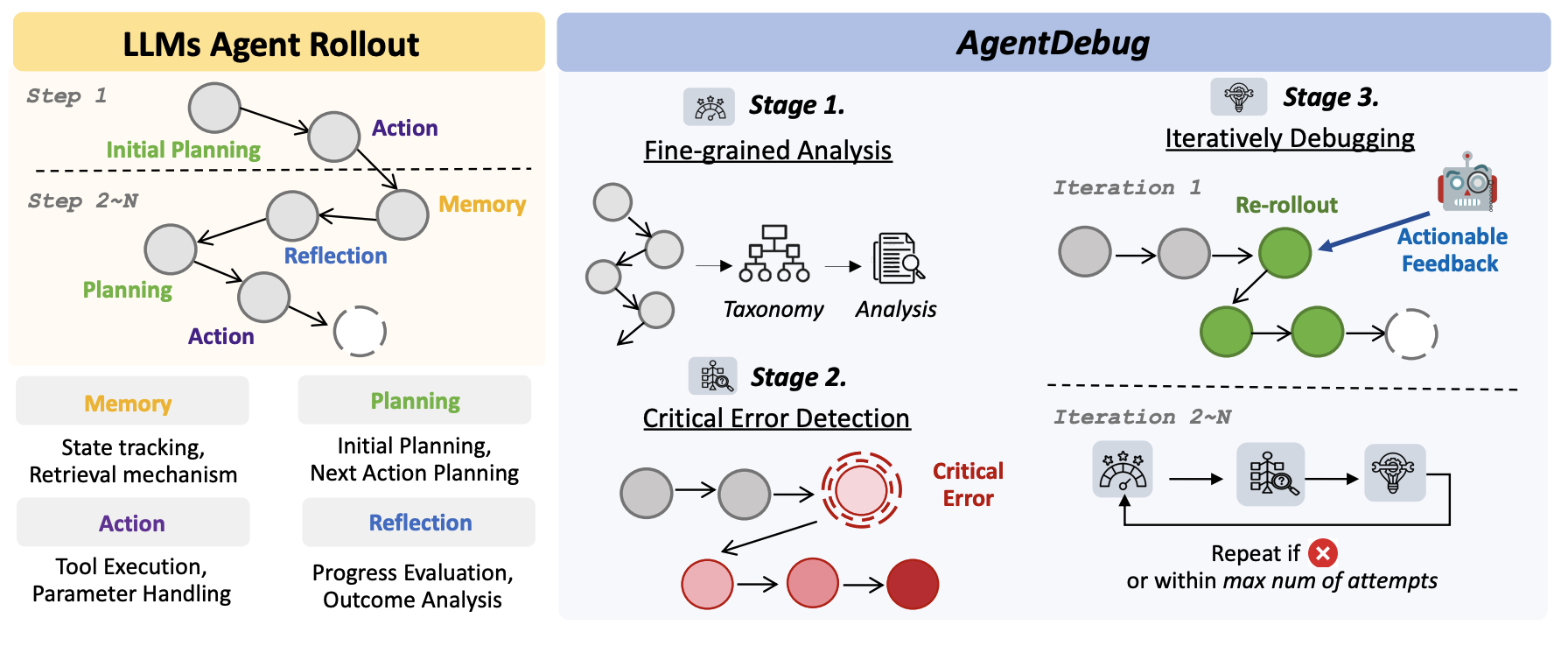
Where LLM Agents Fail and How They Can Learn from Failures
Kunlun Zhu, Zijia Liu, Bingxuan Li, Muxin Tian, Yingxuan Yang, Jiaxun Zhang, Pengrui Han, Qipeng Xie, Fuyang Cui, Weijia Zhang, Xiaoteng Ma, Xiaodong Yu, Gowtham Ramesh, Jialian Wu, Zicheng Liu, Pan Lu, James Zou, and Jiaxuan You
Preprint, 2025
arXiv
LLM agents amplify cascading failures, where a single root-cause error propagates through subsequent decisions. We introduce a modular taxonomy of agent failure modes, build the first dataset of annotated failure trajectories, and propose AgentDebug — a debugging framework that isolates root-cause failures and enables agents to iteratively recover.
|
|
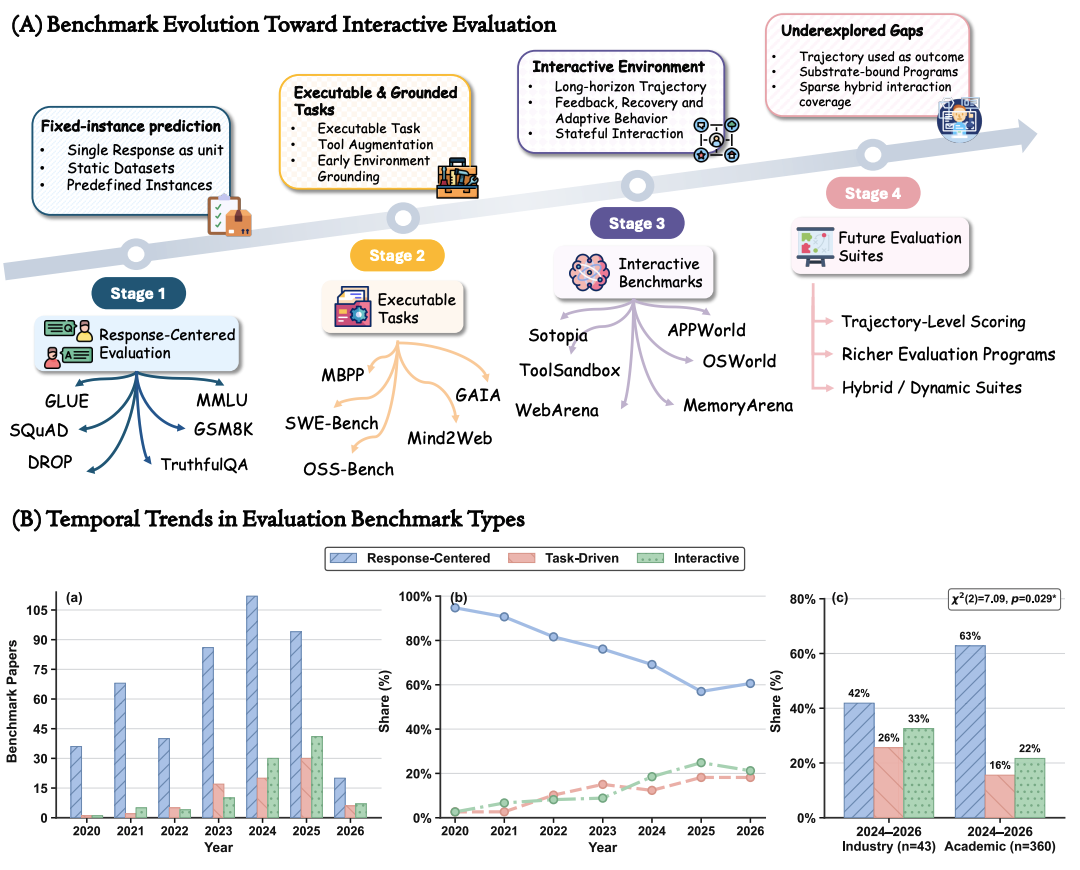
Interactive Evaluation Requires a Design Science
Keyang Xuan*, Peiyang Song*, Pan Lu, Pengrui Han, Wenkai Li, Zhenyu Zhang, Zexue He, Wenyue Hua, Manling Li, Jiaxuan You, Adrian Weller, Yizhong Wang†, and Jiaxin Pei† (* Equal Contribution, † Equal Advising)
Preprint, 2026
arXiv
/
code
AI evaluation is increasingly moving beyond static responses toward systems that act through tools, environments, users, and other agents. But the field risks adding interaction faster than it develops the scientific foundations for evaluating interaction. We argue that interactive evaluation needs a design science, not just more agent benchmarks — defining interactive evaluation, proposing a 2-axis taxonomy, and outlining principles for designs that are interpretable, comparable, and scientifically useful.
|
|